Mysql索引优化实战(分页、JOIN、Count)
Mysql索引优化实战(分页、JOIN、Count)
- 1.分页查询优化
- 1.1 根据自动递增主键的分页查询
- 1.1.1 优化前
- 1.1.2 优化后
- 1.2 根据非主键字段排序的分页查询
- 1.2.1 未优化前
- 1.2.2 优化后
- 2.表JOIN关联优化
- 2.1 嵌套循环连接(NLJ) has index
- 2.1.1 JOIN
- 2.1.2 LEFT JOIN
- 2.1.3 RIGHT JOIN
- 2.2 基于块的嵌套循环连接(BNL) not has index
- 2.2.1 JOIN
- 2.2.2 LEFT JOIN
- 2.2.3 RIGHT JOIN
- 2.3 对于关联SQL的优化
- 3.表COUNT 查询优化
- 3.1 COUNT(*)
- 3.2 COUNT(1)
- 3.3 COUNT(主键)
- 3.4 COUNT(字段)
- 3.5 COUNT 常见优化方法
- 3.5.1 查询mysql维护的总行数(仅针对MyISAM引擎)
- 3.5.2 show table status
- 3.5.3 将总数维护到缓存中
- 3.5.4 在数据库中新增计数表
1.分页查询优化
-- 表结构
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=100004 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
mysql> select * from employees limit 80000,10;
表示从表 employees 中取出从 10001 行开始的 10 行记录, 看着只有10条记录其实是先查询出10010条记录 然后抛弃前10000条记录 数据量越大效率越低
1.1 根据自动递增主键的分页查询
1.1.1 优化前
SELECT * FROM employees limit 80000,5
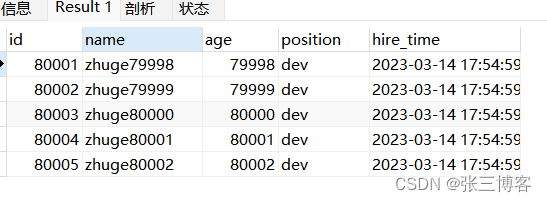

1.1.2 优化后
SELECT * FROM employees WHERE id>80000 limit 5
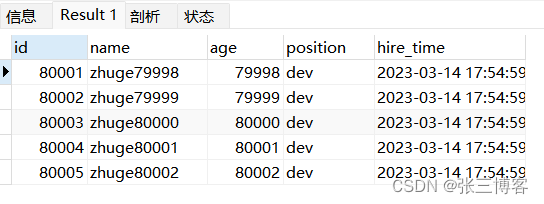

- 通过两者的比对可以发现扫描行数变少 自然查询效率也会更快 但是以上优化必须是主键自增且连续的数据
1.2 根据非主键字段排序的分页查询
1.2.1 未优化前
SELECT * FROM employees ORDER BY name limit 90000,5
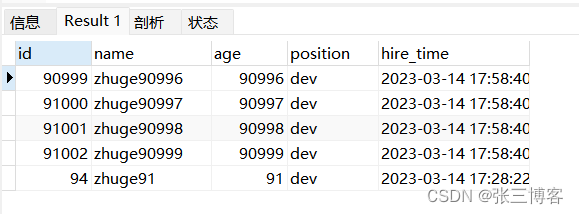

1.2.2 优化后
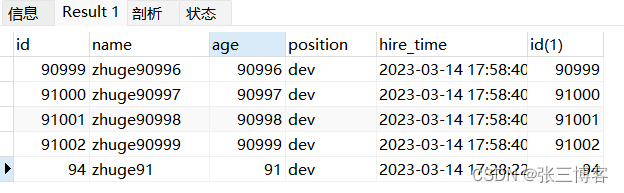
select * from employees e inner join (select id from employees order by name limit 90000,5) ed
on e.id = ed.id;

- 优化前存在的问题 虽然name有索引 但是由于需要频繁的回表 所以mysql选择了在聚簇索引上进行查询 这也就是为什么没有使用索引 此处可以看到优化前使用的是Using filesort(文件排序)
- 优化后使用了二级索引
idx_name_age_position通过采用二级索引的方式先查询到id 再通过join来进行联查 可以看到查询效率优化了一般 同样这里也可以看到采用的 Using index(索引排序)
2.表JOIN关联优化
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table t2 like t1;
drop procedure if exists insert_t1;
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1(a,b) values(i,i);
set i=i+1;
end while;
end;;
call insert_t1();
drop procedure if exists insert_t2;
create procedure insert_t2()
begin
declare i int;
set i=1;
while(i<=100)do
insert into t2(a,b) values(i,i);
set i=i+1;
end while;
end;;
call insert_t2();
2.1 嵌套循环连接(NLJ) has index
- 一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。
2.1.1 JOIN
- t2为驱动表 t1为被驱动表
EXPLAIN SELECT * FROM t1 inner join t2 ON t1.a=t2.a

2.1.2 LEFT JOIN
- t1为驱动表 t2为被驱动表
EXPLAIN SELECT * FROM t1 left join t2 ON t1.a=t2.a

2.1.3 RIGHT JOIN
- t2为驱动表 t1为被驱动表
EXPLAIN SELECT * FROM t1 right join t2 ON t1.a=t2.a

从执行计划中可以看到这些信息:
- 驱动表是 t2,被驱动表是 t1。先执行的就是驱动表(执行计划结果的id如果一样则按从上到下顺序执行sql);优化器一般会优先选择小表做驱动表。所以使用 inner join 时,排在前面的表并不一定就是驱动表。
- 当使用left join时,左表是驱动表,右表是被驱动表,当使用right join时,右表时驱动表,左表是被驱动表,当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表。
- 使用了 NLJ算法。一般 join 语句中,如果执行计划 Extra 中未出现 Using join buffer 则表示使用的 join 算法是 NLJ。
2.2 基于块的嵌套循环连接(BNL) not has index
把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比。
2.2.1 JOIN
EXPLAIN SELECT * FROM t1 inner join t2 ON t1.b=t2.b

上面sql的大致流程如下:
- 把 t2 的所有数据放入到 join_buffer 中
- 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
- 返回满足 join 条件的数据
2.2.2 LEFT JOIN
EXPLAIN SELECT * FROM t1 left join t2 ON t1.b=t2.b

上面sql的大致流程如下:
- 把 t1的所有数据放入到 join_buffer 中
- 把表 t2 中每一行取出来,跟 join_buffer 中的数据做对比
- 返回满足 join 条件的数据
2.2.3 RIGHT JOIN
EXPLAIN SELECT * FROM t1 right join t2 ON t1.b=t2.b

上面sql的大致流程如下:
- 把 t2 的所有数据放入到 join_buffer 中
- 把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比
- 返回满足 join 条件的数据
2.3 对于关联SQL的优化
- 关联字段加索引 尽量让mysql 使用NLJ算法
- 小表驱动大表
- in和exsits优化
3.表COUNT 查询优化
EXPLAIN select count(1) from employees;
EXPLAIN select count(id) from employees;
EXPLAIN select count(name) from employees;
EXPLAIN select count(*) from employees;

字段有索引:count(*)≈count(1)>count(字段)>count(主键)
字段无索引:count(*)≈count(1)>count(主键)>count(字段)
3.1 COUNT(*)
- mysql并不会把全部字段取出来,而是专门做了优化,不取值,按行累加,效率很高,所以不需要用count(列名)或count(常量)来替代 count(*)
3.2 COUNT(1)
- COUNT(1) 走二级索引 根据mysql的优化机制来选择
- 跟count(字段)执行过程类似,不过count(1)不需要取出字段统计,就用常量1做统计,count(字段)还需要取出字段,所以理论上count(1)比count(字段)会快一点。
3.3 COUNT(主键)
- 走主键索引,所以count(主键 id)>count(字段)
- 在5.7以后如果有二级索引 mysql会优先选择使用二级索引
3.4 COUNT(字段)
- 字段有索引走二级索引 没有索引走全表扫描
3.5 COUNT 常见优化方法
3.5.1 查询mysql维护的总行数(仅针对MyISAM引擎)
- MyISAM存储引擎的表的总行数会被mysql存储在磁盘上
- InnoDB 存储引擎不会
3.5.2 show table status
- 采用此查询方式性能高(大概值)
show table status like 't1'

3.5.3 将总数维护到缓存中
- 插入或者删除的时候维护缓存中的总行数,存在事务一致性的问题
3.5.4 在数据库中新增计数表
- 插入和删除表数据维护计数表 可以保证在同一事务中