Spark 集群搭建(多种方式)
Spark 集群搭建(多种方式)
- 一、local 模式
- 1.解压文件
- 2.使用
- 3.local 模式提交
- 二、Standalone 模式
- 1.解压文件
- 2.配置文件
- 3.分发文件
- 4.启动
- 5.standalone 模式提交
- 三、YARN 模式
- 1.配置环境变量
- 2.修改 yarn 配置文件
- 3.启动集群
- 4.YARN 模式提交
- 5.YARN 提交参数
- 四、Spark on Hive
- 1.文件复制
- 2.驱动拷贝
- 3.重启集群并验证
前言:本文中使用的 Spark 版本为 spark-3.0.0、Hadoop 版本为 hadoop-3.1.3、Hive 版本为 hive-3.1.2、MySQL 版本为 MySQL 5.7。
Hadoop 搭建参考:Hadoop 完全分布式搭建(超详细)
Hive 搭建参考:Hive 搭建(将 MySQL 作为元数据库
一、local 模式
不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于简单演示与测试。
1.解压文件
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
2.使用
解压完成后,我们就可以直接来使用 Spark 了。
# 切换到解压目录
cd /opt/module/spark-3.0.0-bin-hadoop3.2
# 进入 spark-shell
bin/spark-shell
简单使用:

3.local 模式提交
使用 local 模式提交任务,圆周率官方案例:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[*] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
3
-
--class表示要执行程序入口主类; -
--masterlocal[*] 部署模式,默认为本地模式,中括号表示分配的虚拟 CPU 核数量; -
指定提交的 jar 包;
-
数字
3是用于设置当前应用的任务数量;

local 模式就是这么玩的,适合做本地测试,运行一些 jar 包等等。
二、Standalone 模式
Spark 自身节点运行的模式,也称为独立部署模式。
1.解压文件
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
# 更改名称
cd /opt/module
mv /opt/module/spark-3.0.0-bin-hadoop3.2 spark-standalone
2.配置文件
进入解压后路径下的 conf 目录
cd /opt/module/spark-standalone/conf
配置 slaves.template 文件
# 先将模板文件复制
cp slaves.template slaves
# 编辑 slaves 文件
vi slaves
# 在其中添加当前工作的节点(更换为你自己的主机):
master
slave1
slave2
配置 spark-env.sh.template 文件
# 先将模板文件复制
cp spark-env.sh.template spark-env.sh
# 编辑 spark-env.sh 文件
vi spark-env.sh
# 在其中添加 JDK 并指定主机与端口:
export JAVA_HOME=/opt/module/jdk1.8.0_212
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
3.分发文件
将 standalone 的安装目录分发给其它的从机。
# 切换到 standalone 模式的安装目录
cd /opt/module
scp -r spark-standalone/ slave1:/opt/module/
scp -r spark-standalone/ slave2:/opt/module/
4.启动
# 切换到 standalone 模式的安装目录下
cd /opt/module/spark-standalone
# 启动
sbin/start-all.sh
启动完成后,可以进入浏览器界面查看运行情况:http://192.168.10.10:8080/
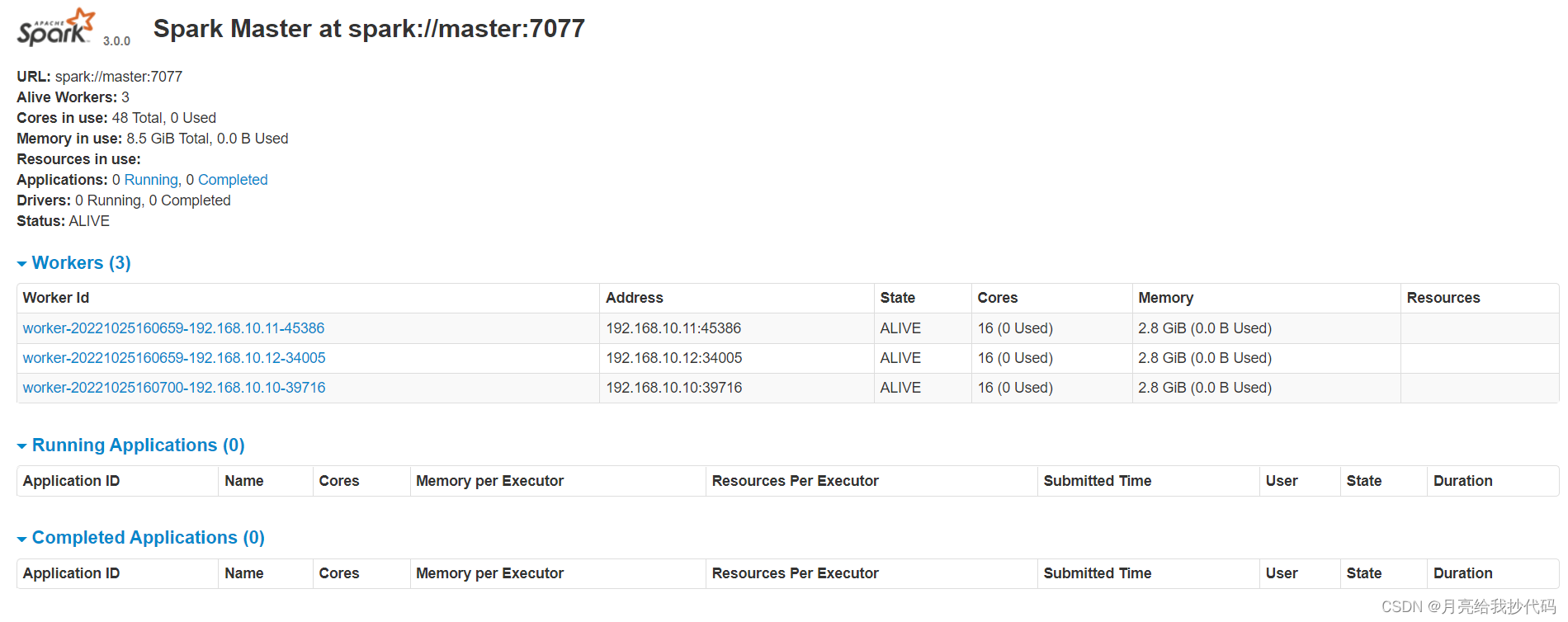
5.standalone 模式提交
使用 standalone 模式提交任务,圆周率官方案例:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
3
注意 --master 参数提交时指定的部署模式!
运行后,我们打开 web 界面 http://192.168.10.10:8080/,可以查看运行的状态:

到此为止,standalone 模式部署完成。
三、YARN 模式
YARN 模式建立在 standalone 模式之上,所以这里就不重复赘述了。请先部署好 standalone 模式,然后在其基础上来建立 YARN 模式。
1.配置环境变量
vi /etc/profile
#在末尾添加如下内容:
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
#SPARK ON YARN
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
# hadoop 3.0 版本以上的无需配置如下这项:
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
分发环境变量到各个主机中,并使其立即生效:source /etc/profile
2.修改 yarn 配置文件
cd $HADOOP_HOME/etc/hadoop
vi yarn-site.xml
#添加两个属性:
<!-- 是否检查物理内存,默认为true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否检查虚拟内存,默认为true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
pmem 检查物理内存,容器使用的物理内存不能超过我们限定的内存大小,超出则默认 kill 掉。
vmem 检查虚拟内存,容器使用的虚拟内存不能超过我们设置的虚拟内存大小,超出则默认 kill 掉。
同步 yarn-site.xml 文件到各个主机中
rsync -r $HADOOP_HOME/etc/hadoop/yarn-site.xml slave1:$HADOOP_HOME/etc/hadoop/yarn-site.xml
rsync -r $HADOOP_HOME/etc/hadoop/yarn-site.xml slave2:$HADOOP_HOME/etc/hadoop/yarn-site.xml
3.启动集群
如果是在配置文件修改前启动的,需要先停止,然后重新启动!
# 启动 Hadoop 集群
# 主节点
start-dfs.sh
# resoucemanager 节点
start-yarn.sh
# 启动 Spark
$SPARK_HOME/sbin/start-all.sh
4.YARN 模式提交
使用 YARN 模式提交任务,圆周率官方案例:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--num-executors 3 \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
3
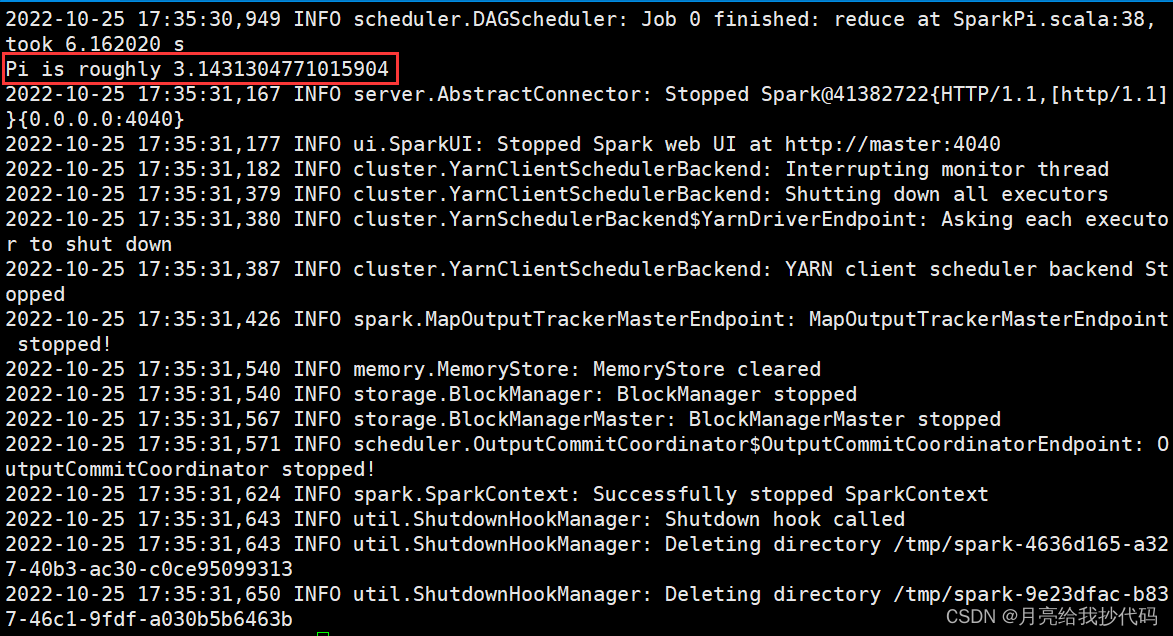
我们可以通过访问 web 界面来查看以 YARN 提交应用的运行情况:http://192.168.10.11:8088/(域名为你的 ResourceManager 节点地址,端口不变)

5.YARN 提交参数
| 名称 | 说明 |
|---|---|
| –num-executors | 配置 Executor 的数量 |
| –executor-memory | 配置每个 Executor 的内存大小 |
| –executor-cores | 配置每个 Executor 的虚拟 CPU core 数量 |
| –driver-memory | driver 的内存大小 |
| –deploy-mode | 指定 YARN 的运行模式,可选:[client / cluster ],默认为 client |
YARN 两种运行模式的区别:
client 模式(默认):Driver 运行在 Client 上,应用程序运行结果会在客户端显示,所有适合运行结果有输出的应用程序(如:spark-shell)。
cluster模式:Driver 程序在 YARN 中运行,Driver 所在的机器是随机的,应用的运行结果不能在客户端显示只能通过 YARN 查看,所以最好运行那些将结果最终保存在外部存储介质(如:HDFS、Redis、MySQL)而非标准输出的应用程序,客户端的终端显示的仅是作为 YARN 任务的简单运行状况。
四、Spark on Hive
Spark on Hive 模式建立在 standalone 模式之上。
1.文件复制
复制 Hadoop 的 hdfs-site.xml 配置文件到 Spark 中的配置目录 conf 中
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf
复制 Hive 的 hive-site.xml 配置文件到 Spark 中的配置目录 conf 中
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
2.驱动拷贝
将 MySQL 驱动拷贝到 Spark 中的 jars 目录下。
cp mysql-connector-java-5.1.37-bin.jar $SPARK_HOME/jars
3.重启集群并验证
# 关闭 Hadoop
# 主节点
stop-dfs.sh
# resoucemanager 节点
stop-yarn.sh
# 启动 Hadoop
# 主节点
start-dfs.sh
# resoucemanager 节点
start-yarn.sh
进入 spark-shell 验证 Spark on Hive 是否部署成功:
spark-shell
# 查询当前创建的所有库
spark.sql("show databases").show

可以看到,我们的 Spark on Hive 运行模式已经部署成功啦!